
Представляю вашему вниманию недавнюю новость из мира науки и технологий. Я считаю, развитие ИИ сильно повлияет на наш современный мир и, конечно же, на игры. Сложно даже представить, какими будут ММО с использованием ИИ, а главное: как его станут использовать.
Группа исследователей из Массачусетского технологического института и Нью-Йоркского университета разработала новую систему искусственного интеллекта, которая оказалась способной ввести в заблуждение людей-судей когда дело коснулось рисования символов, напоминающих буквы какого-то экзотического алфавита. Этот эксперимент, результаты которого были опубликованы в журнале Science, можно рассматривать как прохождение визуального варианта теста Тьюринга, предназначенного для определения степени совершенства систем искусственного интеллекта.
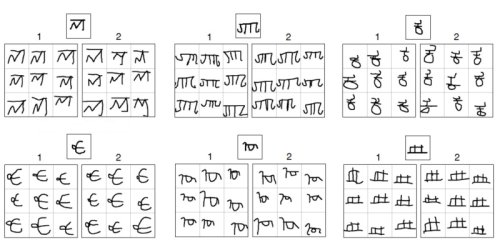
В ходе эксперимента человеку и компьютеру показали незнакомый им символ, который напоминает некую букву. На приведенном немного ниже изображении вы можете увидеть примеры таких символов.
В первой части эксперимента человек и компьютер должны были внести изменения в символ таким образом, чтобы он немного исказился, но оставался после этого узнаваемым. В других частях теста человеку и компьютеру выдали целую серию символов и им требовалось создать новый символ, который вписывается в представленную серию.

После того, как человек и компьютер выполнили поставленные задачи, команда судей попыталась определить, какие из символов были нарисованы системой искусственного интеллекта. Через некоторое время, проведенное в разглядывании нарисованных «закорлючек», судьи вынесли свое решение, а точность определения ими работы искусственного интеллекта составила 50 процентов, другими словами, они не смогли однозначно отделить работу человека от работы компьютера.
Все это походит на весьма странный эксперимент, но у него имеется очень глубокое и далекоидущее значение. В обычных условиях системы искусственного интеллекта проходят предварительное обучение на больших наборах данных прежде, чем они самостоятельно смогут решать определенные задачи. Человек, в отличие от этого, способен учиться «на лету», выполняя работу сразу и постепенно совершенствуя свои навыки.
В новой системе искусственного интеллекта как раз и была реализована технология «обучения на лету» в основу которой легли самообучающиеся алгоритмы Bayesian Program Learning. Эти алгоритмы подходят к проблеме обучения точно таким же образом, которым люди изучают неизвестные им до этого понятия.
«Сначала наша программа составляет весьма грубую модель данных, с которыми ей предстоит работать. После этого специальные алгоритмы заполняют пробелы в этой модели, анализируя результаты своей деятельности или примеры подобной деятельности, сделанной людьми или другими системами».
В данном случае программа определила, что процесс рисования символов состоит из так называемых «штрихов», разделенных отрывом ручки от бумаги. Штрихи, в свою очередь, состоят из серии более мелких действий, разделенных точками, в которых скорость ручки равна нулю. Составив такую обобщенную модель, система искусственного интеллекта произвела анализ движений ручки при рисовании людьми символов из различных алфавитов, и этот анализ дал в ее «руки» возможность рисования новых и повторения уже нарисованных символов.
«Множество систем были созданы с целью распознавания символов» – рассказывает Джош Тененбаум (Josh Tenenbaum), один из исследователей, – «Такие системы терпят неудачу в идентификации символа, если его часть прорисована нечетко или не нарисована вообще, как это часто бывает в рукописном тексте. Наша система искусственного интеллекта свободна от этого недостатка, ведь она не занимается оценкой формы символа, а производит анализ порядка его начертания. Система определяет, из чего состоит каждый символ и ей не представляет труда идентифицировать его даже тогда, когда в рисунке отсутствуют целые части».
И в заключение приводим правильные ответы к третьему рисунку. Искусственный интеллект является «автором» 1, 2 и 1 наборов символов в первой строке, и 2, 1 и 1 наборов символов во второй строке.


53 комментария
… в качестве игроков.
В любом случае нужен фундамент для первой пробы (для человека это могут быть рефлексы и инстинкты, т.е. результат биологического обучения). Плохо понимаю, чем одно обучение будет «на лету», а другое — нет.
Как и на чем она это определила?
А вот формулирование принципа, стоящего за рукописными алфавитами — интересное достижение. Особенно, если система самообучения способна выявлять подобное.
Практичнее было бы решать задачи Бонгарда, но кто про них слышал ))
За ней весело машут руками психология с сестрой ее психиатрией и прочие этологи/когнитивисты.
Даже тест Тьюринга уже наполовину использует психологию.
А уж как отличить самосознание и момент самоосознания от имитации оных хорошо проапгрейженной «Элизой», вообще вопрос затрагивающий довольно много наук включая философию.
Вообще в ИИ-переводчик мне слабо верится. В каждом языке есть мета-уровень связный с определенной культурой. Это как объять необъятное.
Записал в книжечку, постараюсь напомнить лет эдак через десять.
Потому что по сути у каждого в голове есть своя китайская комната, просто очень большая и сложная.
И если естественный интеллект переступил границу понимания, то значит и китайская комната на это способна. («как» это на несколько порядков более сложный вопрос).
Конечно понимание китайской грамоты в «китайской комнате» ограничено сопоставлением символов без привязки к звучанию или конкретным объектам/действиям. Но насколько это отличается от понимания некоторых областей математики или квантовой физики, где всё сводится к набору формул без возможности рассмотреть объект собственными глазами?
Задавались ли вы вопросом, насколько ребёнок, отвечая на стандартные вопросы, понимает их суть, а насколько это сводится к формуле «на это надо отвечать вот так»? А с вызубренными стишками ещё хуже — в итоге может обнаружиться даже неправильное разбиение этого потока текста на слова.
Наш собственный мозг — та же китайская комната (с несколькими каналами передачи информации, но это не настолько важно). При этом в ней изначально даже нет библиотеки — только маленькая книжка с набором инстинктов. И на формирование базовых принципов, на которых строится то, что мы называем пониманием, уходит несколько первых лет жизни. Да и потом формирование понимания любой новой области обычно существенно отстаёт от набора базы данных.
В общем, с подобного рода понятиями всегда стоит сначала задать вопрос, насколько мы сами достигаем этого и что в этом случае вот это понятие на самом деле из себя представляет. И главная проблема тут — осознание мыслительного процесса, когда в цепочке присутствуют несколько скачков через формирующиеся в раннем детстве или даже генетически обусловленные нейронные цепочки (то самое, когда единственный ответ у большинства людей сводится к вопросу «Ну как это можно не понимать?»)
Тащемто,это то как раз решаемо и довольно давно, при построении интеллектуальных и экспертных систем, например.У меня остается вопрос будет ли работать понимание лишь имея информацию до определенного уровня. Например если я понимаю что есть сплав металлов нужно ли мне понимание физических и химических процессов или и так я смогу применять свое понимание на практике проектируя что-то из этих сплавов.
Для медицины например уже сложнее. Какие признаки человека надо вытащить чтобы поставить нормальный диагноз не всегда понятно, а сами значения могут быть дорогостоящими. Да еще и связи между значениями не всегда формальные. Тут берется эксперт (например доктор мед наук)
наливается ему коньяк, ставится на прогрев утюг с паяльником… и так пока все не расскажети начинается с ним работа по формализации данных (долгая, требующая квалификации как в математике и прикладной области, так и в самих навыках общения и понимания у специалиста), после чего уже строится экспертная/интеллектуальная система.А вот например адекватный машинный перевод даже такими способами уже не берется, там совсем другие подходы с заглядыванием на поле как лингвистики с философией, так и статистики с мат методами.
А еще есть нейронные сети, обучение. генетические алгоритмы и прочее…
Вот когда этого не будет, но будет получено соответствующие решение, это и будет критерием наличия понимания.
Процесс накопления данных и знаний все равно убрать не получится.
Это уже не важно, когда будет такая экспертная система, обученная в смысле обучения ребенка (т.е. самообучение), это будет соответствовать требуемому уровню.
Задачи Бонгарда сейчас как раз решаются, но они достаточно узкоспециализированы (фактически это распознавание и не более) и например в принятии решений их применимость будет нетривиальной как минимум.
К тесту Тьюринга скорее есть вопросы по поводу заведомо нечеловеческого интеллекта, если он будет получен. Или по поводу качественных ботов которые могут его пройти за счет разветвленной и хорошо структурированной БД с не интеллектуальным алгоритмом (за счет того что человек тоже будет действовать механистично).
Это всего лишь один из ответов какого то представителя института (уже не помню) на Китайскую комнату, он более чем спорен и совсем не показывает, что выводы по Китайской комнате не справедливы.
Опять же мы сами думаем по сути китайской комнатой большого объема. Мозг называется.
не со мной, а с Серлем… а уже я, в свою очередь, согласен с Серлем.
Их решают не правильно, отсюда и ваш вывод. Там 100 задач, так вот решением не является решить их по отдельности, решением является решить их одним общим алгоритмом, а это как раз не делается. А если бы это сделали бы — это как минимум был бы “Это — маленький шаг для человека, но огромный — для всего человечества” (увы, детали не формат для этого форума)
или психологическом эксперименте про давление массового сознания)А кто второй лагерь и что специалисты по ИИ проигрывают? А то вот мне как пусть и бывшему в академическом прошлым таким специалистом, интересно стало.
наука не играет в соревнования кто кого победит. ну кроме моментов распределения грантов. Наука а особенно прикладная математика, решает практические задачи. А решать что то чтобы философы подумали о нас хорошо — нет такой задачи перед математикой.
А что они сделали для ИИ, чтобы вообще квалифицированно спорить со специалистами в их области. Потому что вообще то ИИ за пределами знаний экспертов и данных о проблемных областях это много
скучнойвеселой математики, матлогики. матстатистики и оценок сложности алгоритмов перебора. возражения психологов и тем более философов вообще будут вне круга решаемых задач.Они сделали много больше, чем любой другой специалист ИИ (говорю я это являясь последним). Они дали понимание того, что ИИ-специалисты более, чем часто (как в частности, в обсуждаемой статье) «выдают желаемое за действительное».
Только не путайте их с т.н. оракулами ИИ (тут я о них пишу habrahabr.ru/post/148849/)
Тем более искусственного человека никто после серьезного прокола с предсказаниями 60-70х годов делать не собирается уже.
Рад, что вы это понимаете… но посмотрите комментарии других ;)
«М. Таубе пишет: »… классический порочный круг:
1. предлагается конструкция машины, предназначенной для моделирования человеческого мозга, который не описан;
2. подробно описанные характеристики машины полагаются аналогичными характеристикам мозга;
3. затем делается «открытие», что машина ведет себя подобно мозгу; порочность состоит в «открытии» того, что было постулировано"."
1. предлагается моделировать отдельные процессы мозга, а не сам мозг (всевозможные распознавания и переводы которые вообще не факт что моделируют человеческое мышление). Или отдельные части мозга в рамках его описания биологами (нейросети, обучение. нечеткий вывод). Кстати все более и более полного. более того моделируется все что может дать пользу. до эволюционных моделей включительно.
2. 3. вообще вне контекста наук по ИИ. Машина ведет себя подобно мозгу на основе совпадения реакций, выводов и получаемых результатов. Не более. Т.е. автомат распознал капчу или перевел кусок текста — хороший умный аппарат. Не распознал — нехороший и неумный. Соответствие мозгу тут вообще не входит в задачу.
Возвращаемся в начало дискуссии? Вы говорите о слабом ИИ, в то время как тест Тьюринга о сильном ИИ. Его и опровергает Серл, и в самом начале он пишет, что к слабому не имеет ни каких претензий… ну и в такой формулировке два лагеря довольны )
> Машина ведет себя подобно мозгу на основе совпадения реакций, выводов и получаемых результатов.
А вот тут извините, повторю что писал выше
Китайская комната опровергает Тест Тьюринга, а именно то, что о наличии понимания можно судить по внешнему поведению субъекта.
ограничения статистического подхода достаточно известны.
По этому поводу у вашего покорного слуги есть несколько статей ))
Наверно, в качество короткого введения в тему, можно посмотреть следующею популяризацию проблемы habrahabr.ru/post/140470/
Поэтому нет, этого подхода менее чем достаточно.
большинственекоторых случаях. Так что может кому и не достаточно, а Гугл например на этом подходе выдает практические результаты от неплохого поиска до серьезного шага в адекватности перевода.